You might have heard of website crawling before — you may even have a vague idea of what it’s about — but do you know why it’s important, or what differentiates it from web crawling? (yes, there is a difference!)
Search engines are increasingly ruthless when it comes to the quality of the sites they allow into the search results.
If you don’t grasp the basics of optimizing for web crawlers (and eventual users), your organic traffic may well pay the price.
A good website crawler can show you how to protect and even enhance your site’s visibility.
Here’s what you need to know about both web crawlers and site crawlers.
There are roughly seven stages to web crawling:
1. URL Discovery
When you publish your page (e.g. to your sitemap), the web crawler discovers it and uses it as a ‘seed’ URL. Just like seeds in the cycle of germination, these starter URLs allow the crawl and subsequent crawling loops to begin.
2. Crawling
After URL discovery, your page is scheduled and then crawled. Content like meta tags, images, links, and structured data are downloaded to the search engine’s servers, where they await parsing and indexing.
3. Parsing
Parsing essentially means analysis. The crawler bot extracts the data it’s just crawled to determine how to index and rank the page.
3a. The URL Discovery Loop
Also during the parsing phase, but worthy of its own subsection, is the URL discovery loop. This is when newly discovered links (including links discovered via redirects) are added to a queue of URLs for the crawler to visit. These are effectively new ‘seed’ URLs, and steps 1–3 get repeated as part of the ‘URL discovery loop’.
4. Indexing
While new URLs are being discovered, the original URL gets indexed. Indexing is when search engines store the data collected from web pages. It enables them to quickly retrieve relevant results for user queries.
5. Ranking
Indexed pages get ranked in search engines based on quality, relevance to search queries, and ability to meet certain other ranking factors. These pages are then served to users when they perform a search.
6. Crawl ends
Eventually the entire crawl (including the URL rediscovery loop) ends based on factors like time allocated, number of pages crawled, depth of links followed etc.
7. Revisiting
Crawlers periodically revisit the page to check for updates, new content, or changes in structure.
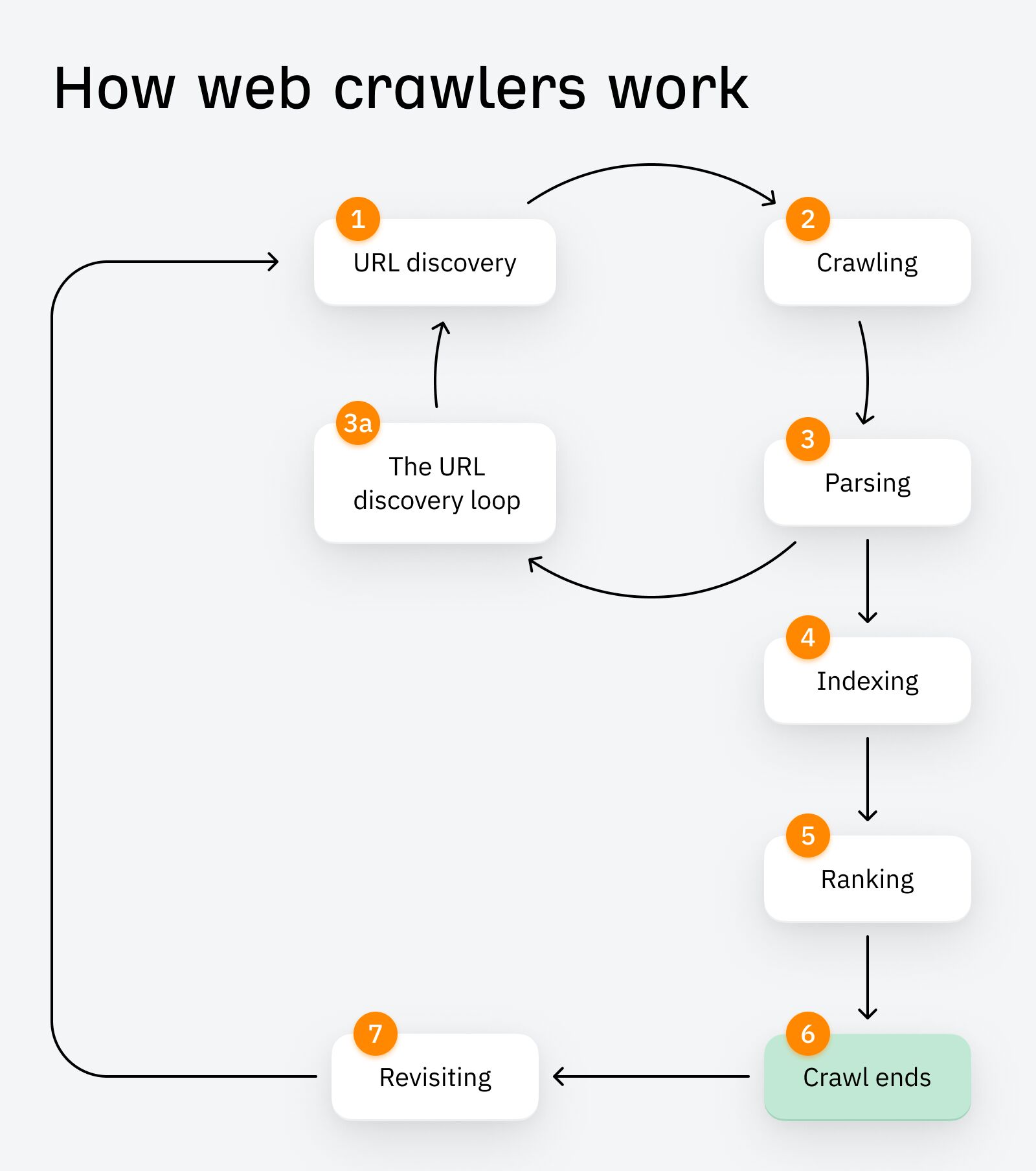
As you can probably guess, the number of URLs discovered and crawled in this process grows exponentially in just a few hops.
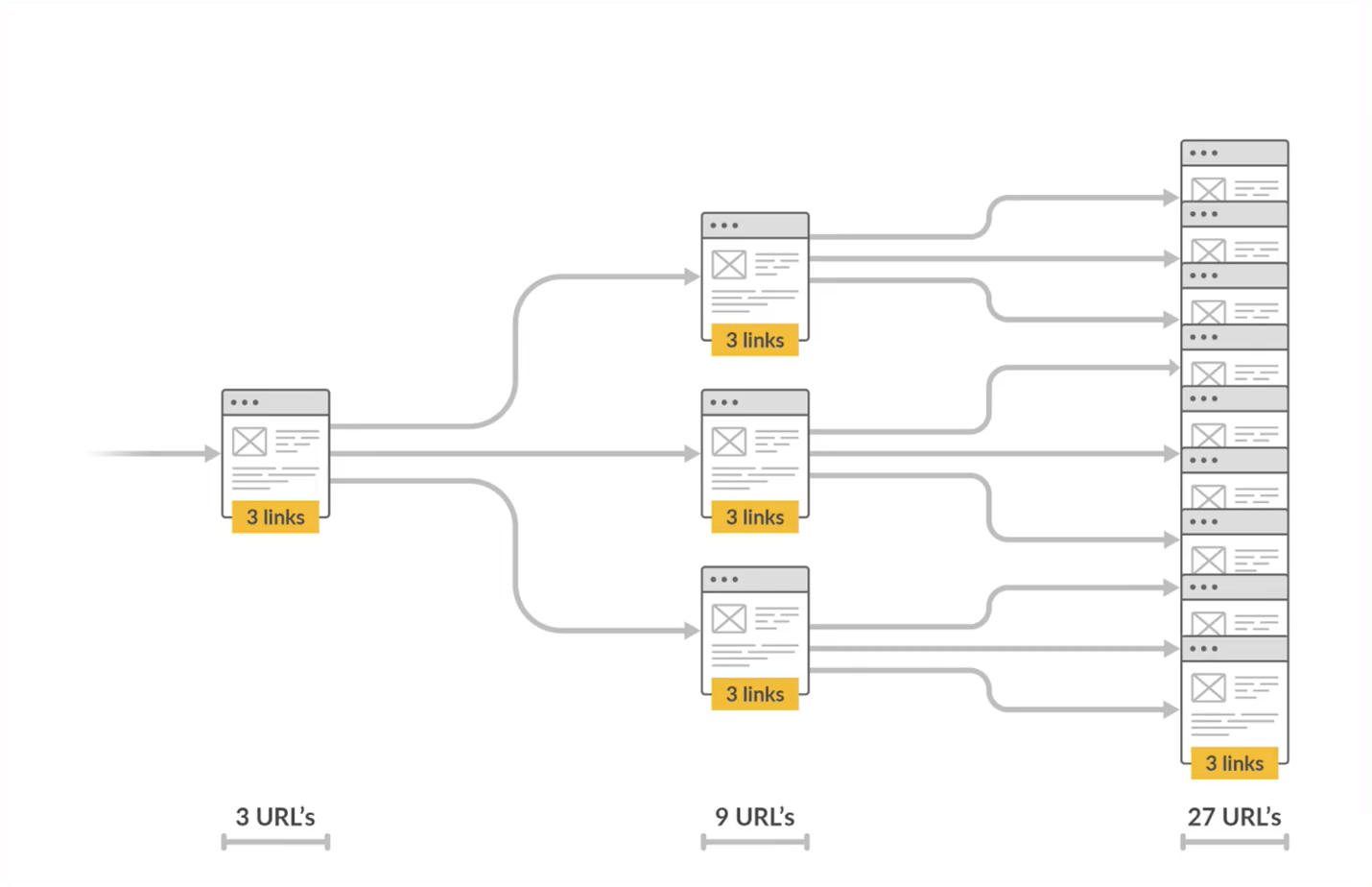
Search engine web crawlers are autonomous, meaning you can’t trigger them to crawl or switch them on/off at will.
You can, however, notify crawlers of site updates via:
XML sitemaps
An XML sitemap is a file that lists all the important pages on your website to help search engines accurately discover and index your content.
Google’s URL inspection tool
You can ask Google to consider recrawling your site content via its URL inspection tool in Google Search Console. You may get a message in GSC if Google knows about your URL but hasn’t yet crawled or indexed it. If so, find out how to fix “Discovered — currently not indexed”.
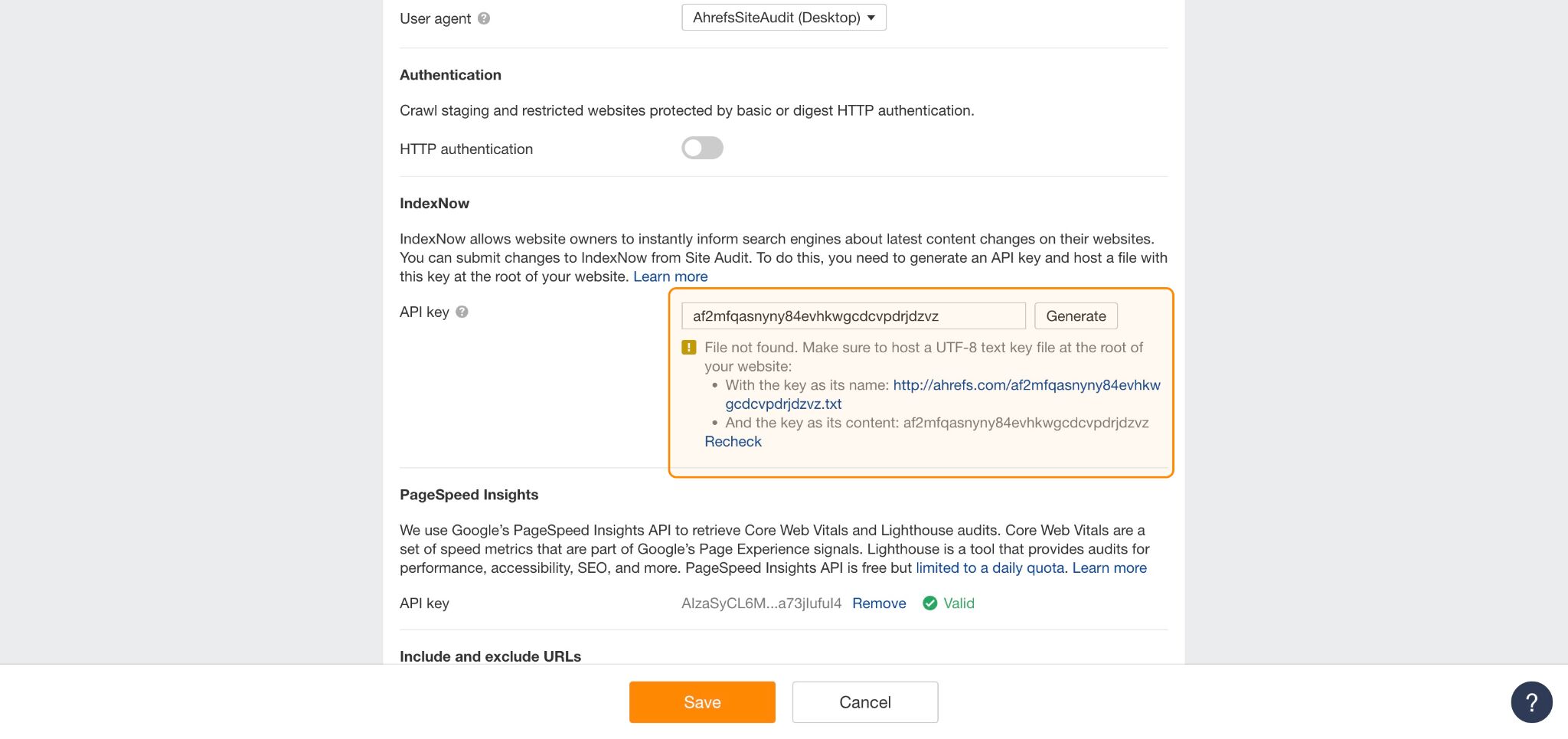
IndexNow
Instead of waiting for bots to re-crawl and index your content, you can use IndexNow to automatically ping search engines like Bing, Yandex, Naver, Seznam.cz, and Yep, whenever you:
- Add new pages
- Update existing content
- Remove outdated pages
- Implement redirects
You can set up automatic IndexNow submissions via Ahrefs Site Audit.
Search engine crawling decisions are dynamic and a little obscure.
Although we don’t know the definitive criteria Google uses to determine when or how often to crawl content, we’ve deduced three of the most important areas.
This is based on breadcrumbs dropped by Google, both in support documentation and during rep interviews.
1. Prioritize quality
Google PageRank evaluates the number and quality of links to a page, considering them as “votes” of importance.
Pages earning quality links are deemed more important and are ranked higher in search results.
PageRank is a foundational part of Google’s algorithm. It makes sense then that the quality of your links and content plays a big part in how your site is crawled and indexed.
To judge your site’s quality, Google looks at factors such as:
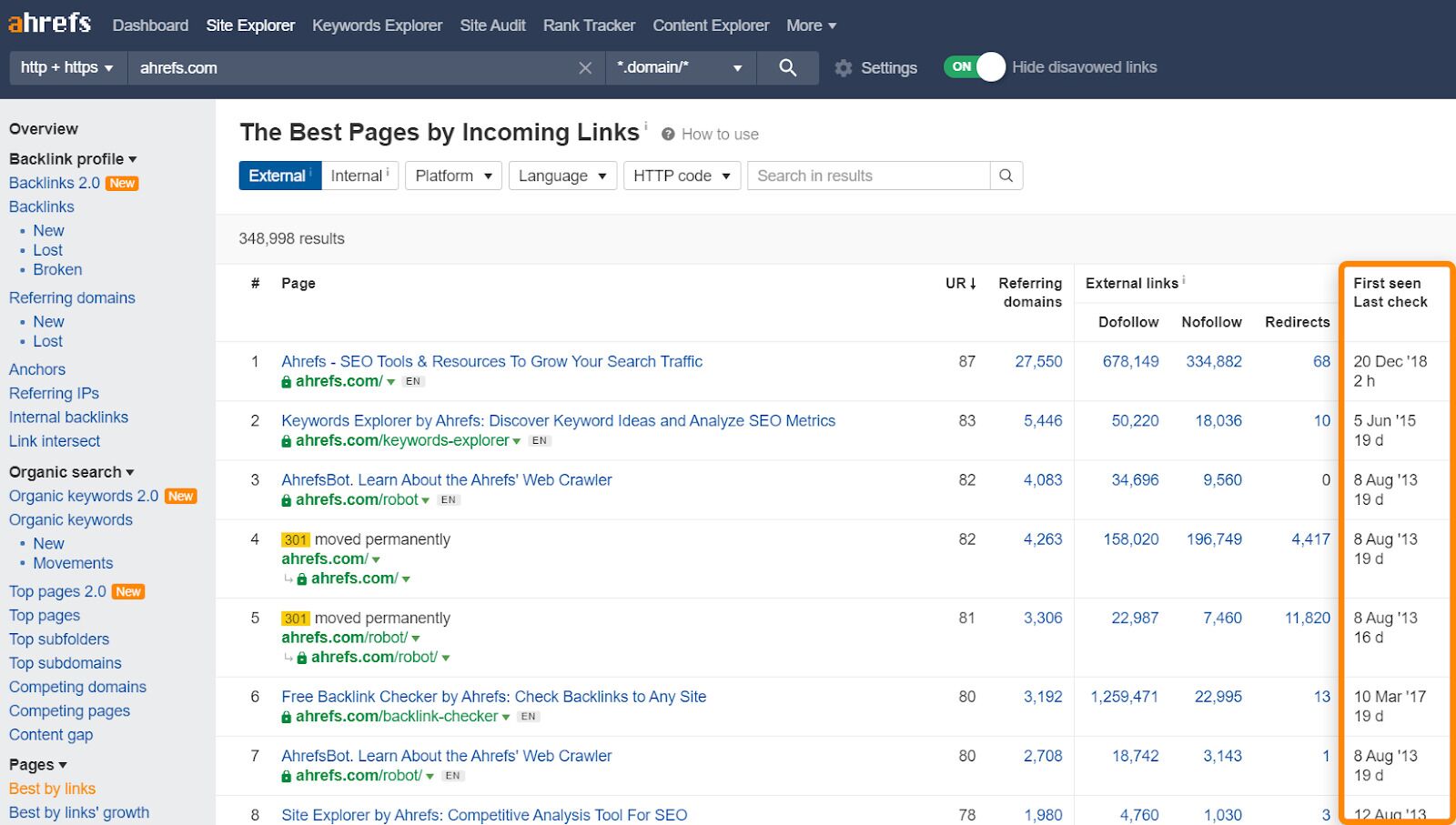
To assess the pages on your site with the most links, check out the Best by Links report.
Pay attention to the “First seen”, “Last check” column, which reveals which pages have been crawled most often, and when.
2. Keep things fresh
According to Google’s Senior Search Analyst, John Mueller…
Search engines recrawl URLs at different rates, sometimes it’s multiple times a day, sometimes it’s once every few months.

But if you regularly update your content, you’ll see crawlers dropping by more often.
Search engines like Google want to deliver accurate and up-to-date information to remain competitive and relevant, so updating your content is like dangling a carrot on a stick.
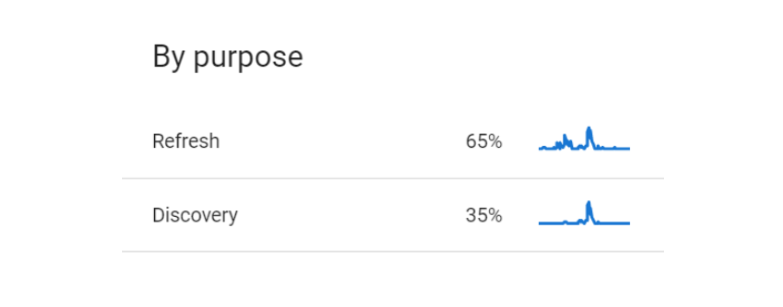
You can examine just how quickly Google processes your updates by checking your crawl stats in Google Search Console.
While you’re there, look at the breakdown of crawling “By purpose” (i.e. percent split of pages refreshed vs pages newly discovered). This will also help you work out just how often you’re encouraging web crawlers to revisit your site.
To find specific pages that need updating on your site, head to the Top Pages report in Ahrefs Site Explorer, then:
- Set the traffic filter to “Declined”
- Set the comparison date to the last year or two
- Look at Content Changes status and update pages with only minor changes
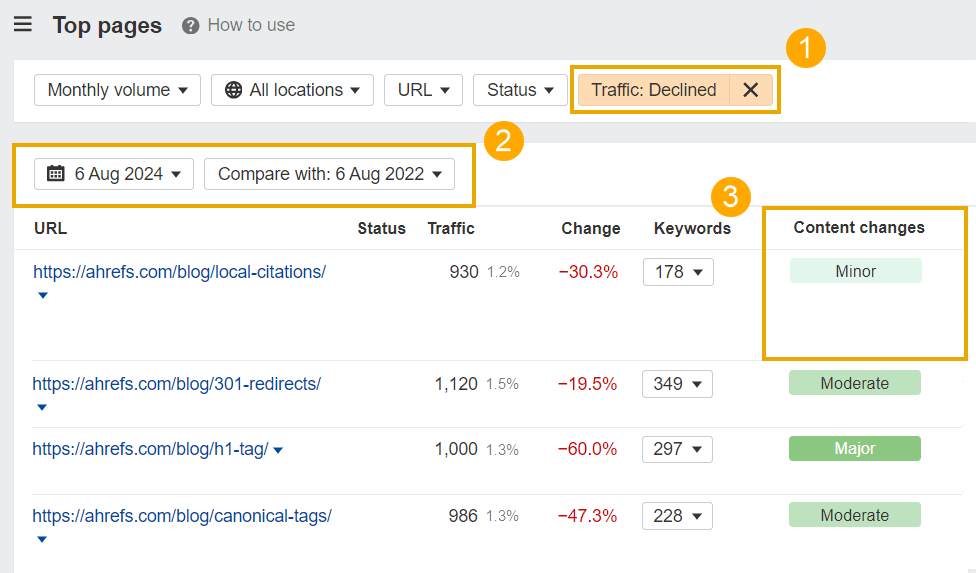
Top Pages shows you the content on your site driving the most organic traffic. Pushing updates to these pages will encourage crawlers to visit your best content more often, and (hopefully) boost any declining traffic.
3. Refine your site structure
Offering a clear site structure via a logical sitemap, and backing that up with relevant internal links will help crawlers:
- Better navigate your site
- Understand its hierarchy
- Index and rank your most valuable content
Combined, these factors will also please users, since they support easy navigation, reduced bounce rates, and increased engagement.
Below are some more elements that can potentially influence how your site gets discovered and prioritized in crawling:
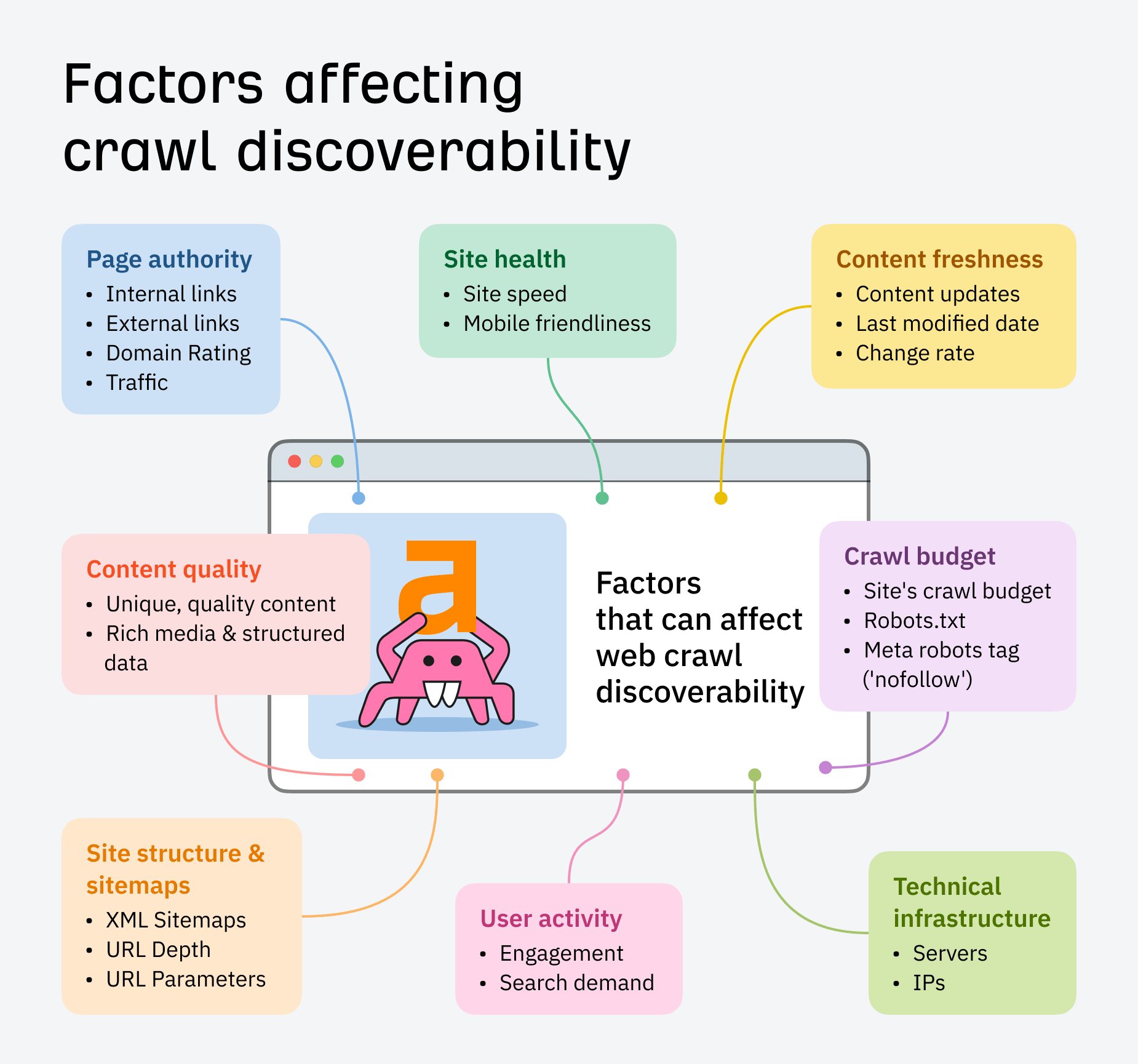
What is crawl budget?
For this reason, each site has a crawl budget, which is the number of URLs a crawler can and wants to crawl. Factors like site speed, mobile-friendliness, and a logical site structure impact the efficacy of crawl budget.
For a deeper dive into crawl budgets, check out Patrick Stox’s guide: When Should You Worry About Crawl Budget?
Web crawlers like Google crawl the entire internet, and you can’t control which sites they visit, or how often.
But you can use website crawlers, which are like your own private bots.
Ask them to crawl your website to find and fix important SEO problems, or study your competitors’ site, turning their biggest weaknesses into your opportunities.
Site crawlers essentially simulate search performance. They help you understand how a search engine’s web crawlers might interpret your pages, based on their:
- Structure
- Content
- Meta data
- Page load speed
- Errors
- Etc
Example: Ahrefs Site Audit
The Ahrefs Site Audit crawler powers the tools: RankTracker, Projects, and Ahrefs’ main website crawling tool: Site Audit.
Site Audit helps SEOs to:
- Analyze 170+ technical SEO issues
- Conduct on-demand crawls, with live site performance data
- Assess up to 170k URLs a minute
- Troubleshoot, maintain, and improve their visibility in search engines
From URL discovery to revisiting, website crawlers operate very similarly to web crawlers – only instead of indexing and ranking your page in the SERPs, they store and analyze it in their own database.
You can crawl your site either locally or remotely. Desktop crawlers like ScreamingFrog let you download and customize your site crawl, while cloud-based tools like Ahrefs Site Audit perform the crawl without using your computer’s resources – helping you work collaboratively on fixes and site optimization.
If you want to scan entire websites in real time to detect technical SEO problems, configure a crawl in Site Audit.
It will give you visual data breakdowns, site health scores, and detailed fix recommendations to help you understand how a search engine interprets your site.
1. Set up your crawl
Navigate to the Site Audit tab and choose an existing project, or set one up.
A project is any domain, subdomain, or URL you want to track over time.
Once you’ve configured your crawl settings – including your crawl schedule and URL sources – you can start your audit and you’ll be notified as soon as it’s complete.
Here are some things you can do right away.
2. Diagnose top errors
The Top Issues overview in Site Audit shows you your most pressing errors, warnings, and notices, based on the number of URLs affected.
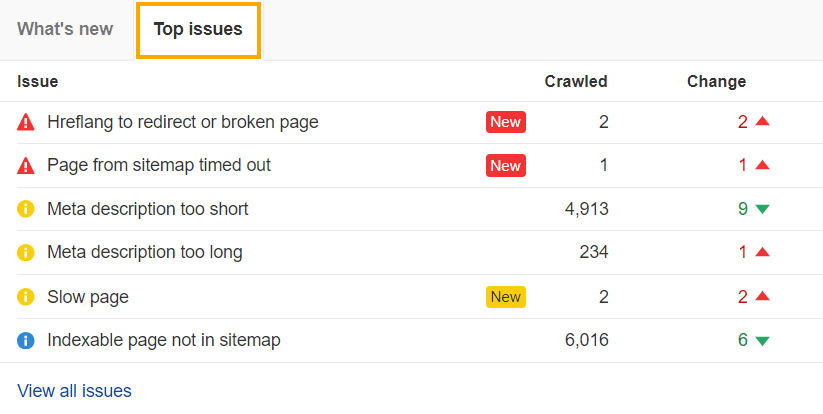
Working through these as part of your SEO roadmap will help you:
1. Spot errors (red icons) impacting crawling – e.g.
- HTTP status code/client errors
- Broken links
- Canonical issues
2. Optimize your content and rankings based on warnings (yellow) – e.g.
- Missing alt text
- Links to redirects
- Overly long meta descriptions
3. Maintain steady visibility with notices (blue icon) – e.g.
- Organic traffic drops
- Multiple H1s
- Indexable pages not in sitemap
Filter issues
You can also prioritize fixes using filters.
Say you have thousands of pages with missing meta descriptions. Make the task more manageable and impactful by targeting high traffic pages first.
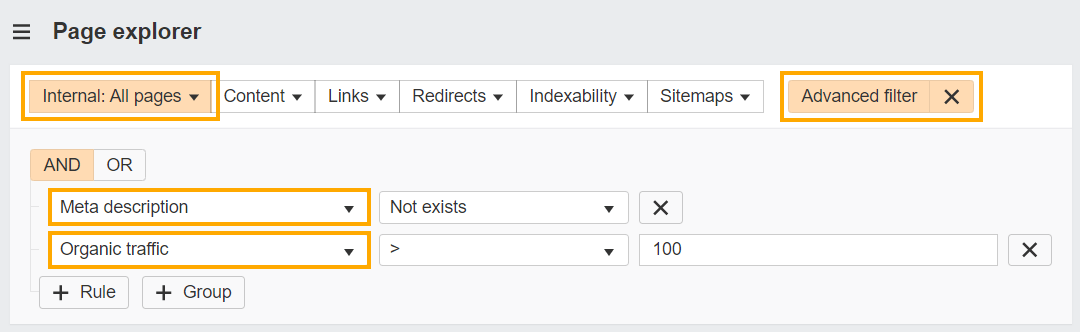
- Head to the Page Explorer report in Site Audit
- Select the advanced filter dropdown
- Set an internal pages filter
- Select an ‘And’ operator
- Select ‘Meta description’ and ‘Not exists’
- Select ‘Organic traffic > 100’
Crawl the most important parts of your site
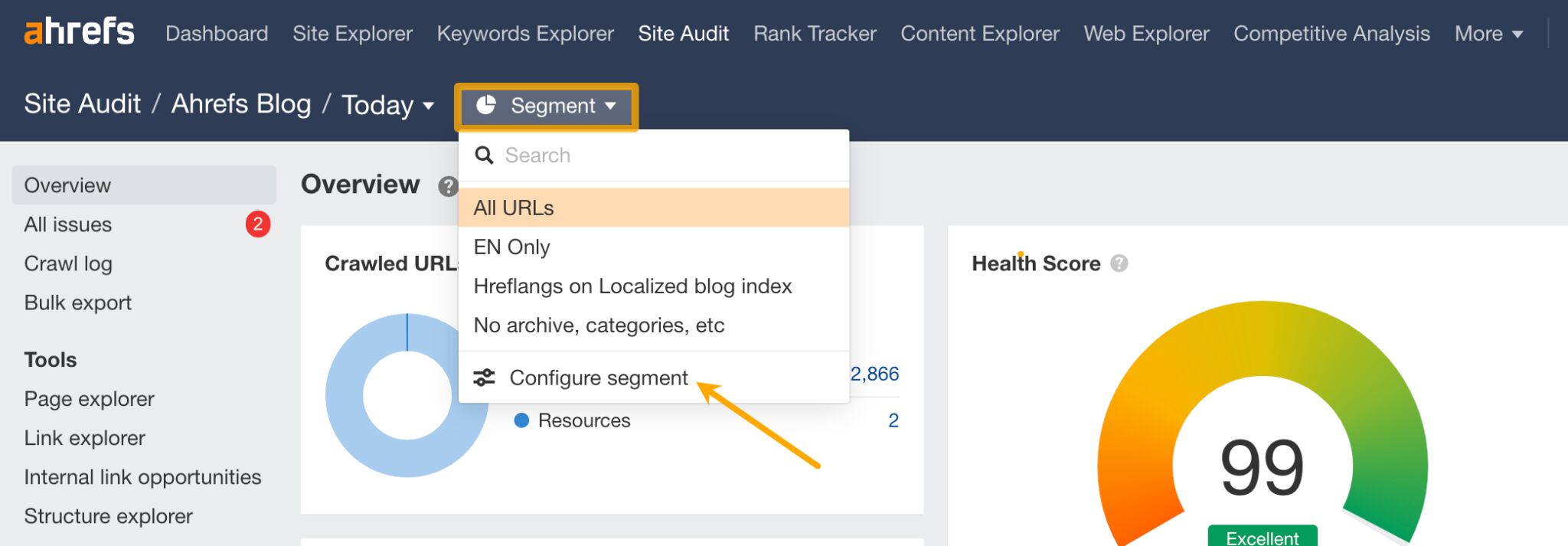
Segment and zero-in on the most important pages on your site (e.g. subfolders or subdomains) using Site Audit’s 200+ filters – whether that’s your blog, ecommerce store, or even pages that earn over a certain traffic threshold.
3. Expedite fixes
If you don’t have coding experience, then the prospect of crawling your site and implementing fixes can be intimidating.
If you do have dev support, issues are easier to remedy, but then it becomes a matter of bargaining for another person’s time.
We’ve got a new feature on the way to help you solve for these kinds of headaches.
Coming soon, Patches are fixes you can make autonomously in Site Audit.
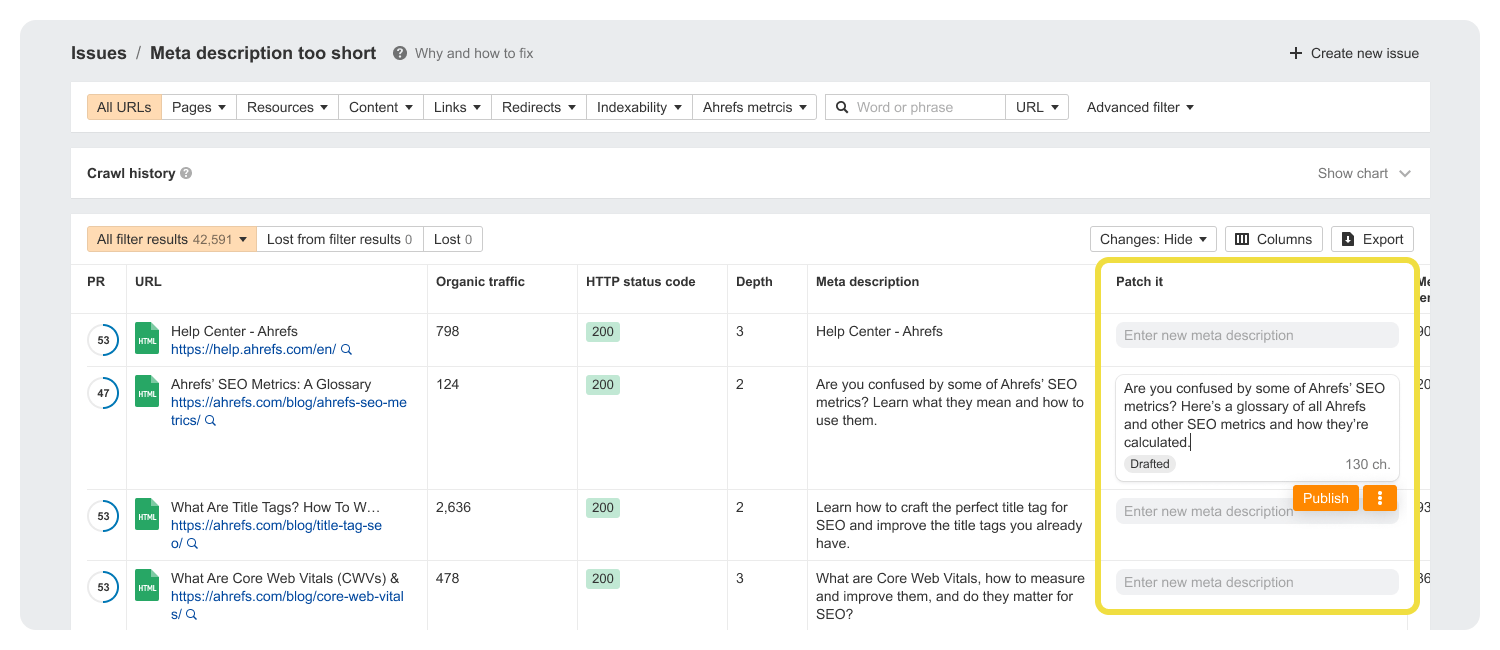
Title changes, missing meta descriptions, site-wide broken links – when you face these kinds of errors you can hit “Patch it” to publish a fix directly to your website, without having to pester a dev.
And if you’re unsure of anything, you can roll-back your patches at any point.

4. Spot optimization opportunities
Auditing your site with a website crawler is as much about spotting opportunities as it is about fixing bugs.
Improve internal linking
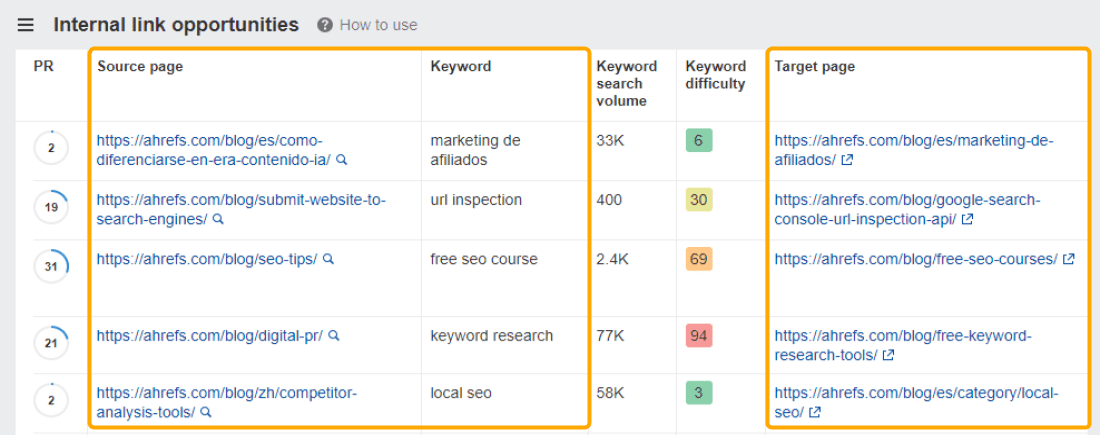
The Internal Link Opportunities report in Site Audit shows you relevant internal linking suggestions, by taking the top 10 keywords (by traffic) for each crawled page, then looking for mentions of them on your other crawled pages.
‘Source’ pages are the ones you should link from, and ‘Target’ pages are the ones you should link to.
The more high quality connections you make between your content, the easier it will be for Googlebot to crawl your site.
Final thoughts
Understanding website crawling is more than just an SEO hack – it’s foundational knowledge that directly impacts your traffic and ROI.
Knowing how crawlers work means knowing how search engines “see” your site, and that’s half the battle when it comes to ranking.