I blocked two of our ranking pages using robots.txt. We lost a position here or there and all of the featured snippets for the pages. I expected a lot more impact, but the world didn’t end.
Warning
I don’t recommend doing this, and it’s entirely possible that your results may be different from ours.
I was trying to see the impact on rankings and traffic that the removal of content would have. My theory was that if we blocked the pages from being crawled, Google would have to rely on the link signals alone to rank the content.
However, I don’t think what I saw was actually the impact of removing the content. Maybe it is, but I can’t say that with 100% certainty, as the impact feels too small. I’ll be running another test to confirm this. My new plan is to delete the content from the page and see what happens.
My working theory is that Google may still be using the content it used to see on the page to rank it. Google Search Advocate John Mueller has confirmed this behavior in the past.
So far, the test has been running for nearly five months. At this point, it doesn’t seem like Google will stop ranking the page. I suspect, after a while, it will likely stop trusting that the content that was on the page is still there, but I haven’t seen evidence of that happening.
Keep reading to see the test setup and impact. The main takeaway is that accidentally blocking pages (that Google already ranks) from being crawled using robots.txt probably isn’t going to have much impact on your rankings, and they will likely still show in the search results.
I chose the same pages as used in the “impact of link” study, except for the article on SEO pricing because Joshua Hardwick had just updated it. I had seen the impact of removing the links to these articles and wanted to test the impact of removing the content. As I said in the intro, I’m not sure that’s actually what happened.
I blocked these two pages on January 30, 2023:
These lines were added to our robots.txt file:
Disallow: /blog/top-bing-searches/Disallow: /blog/top-youtube-searches/
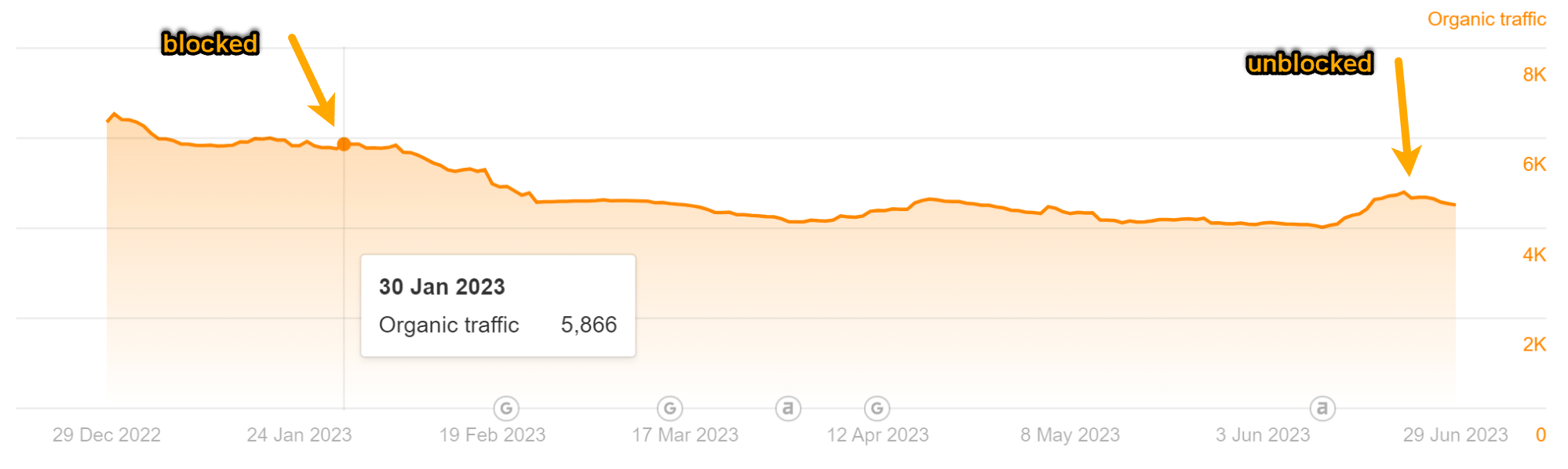
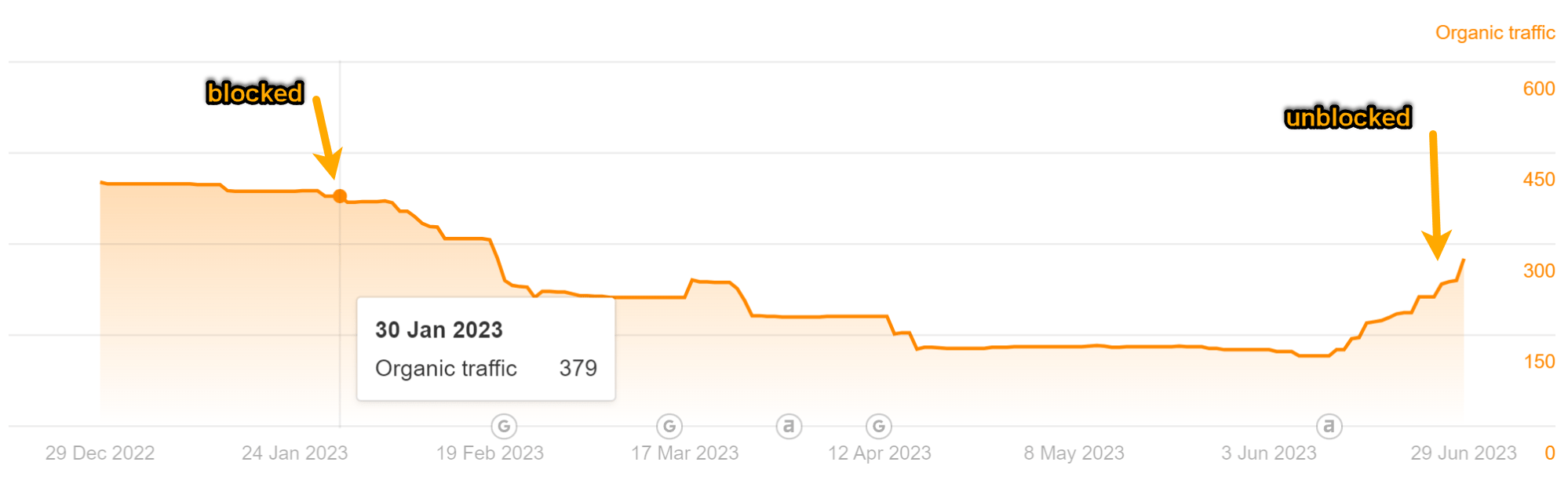
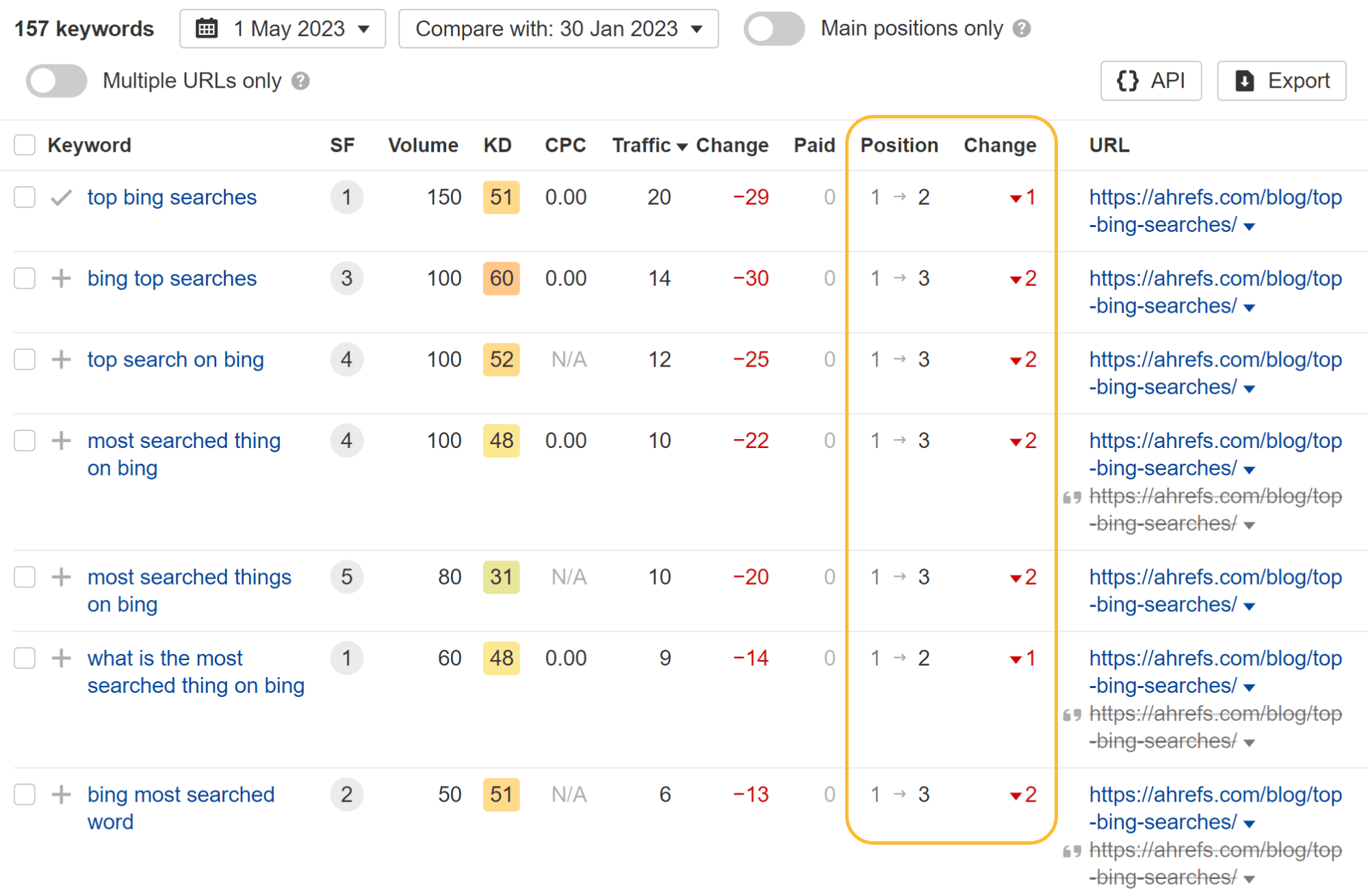
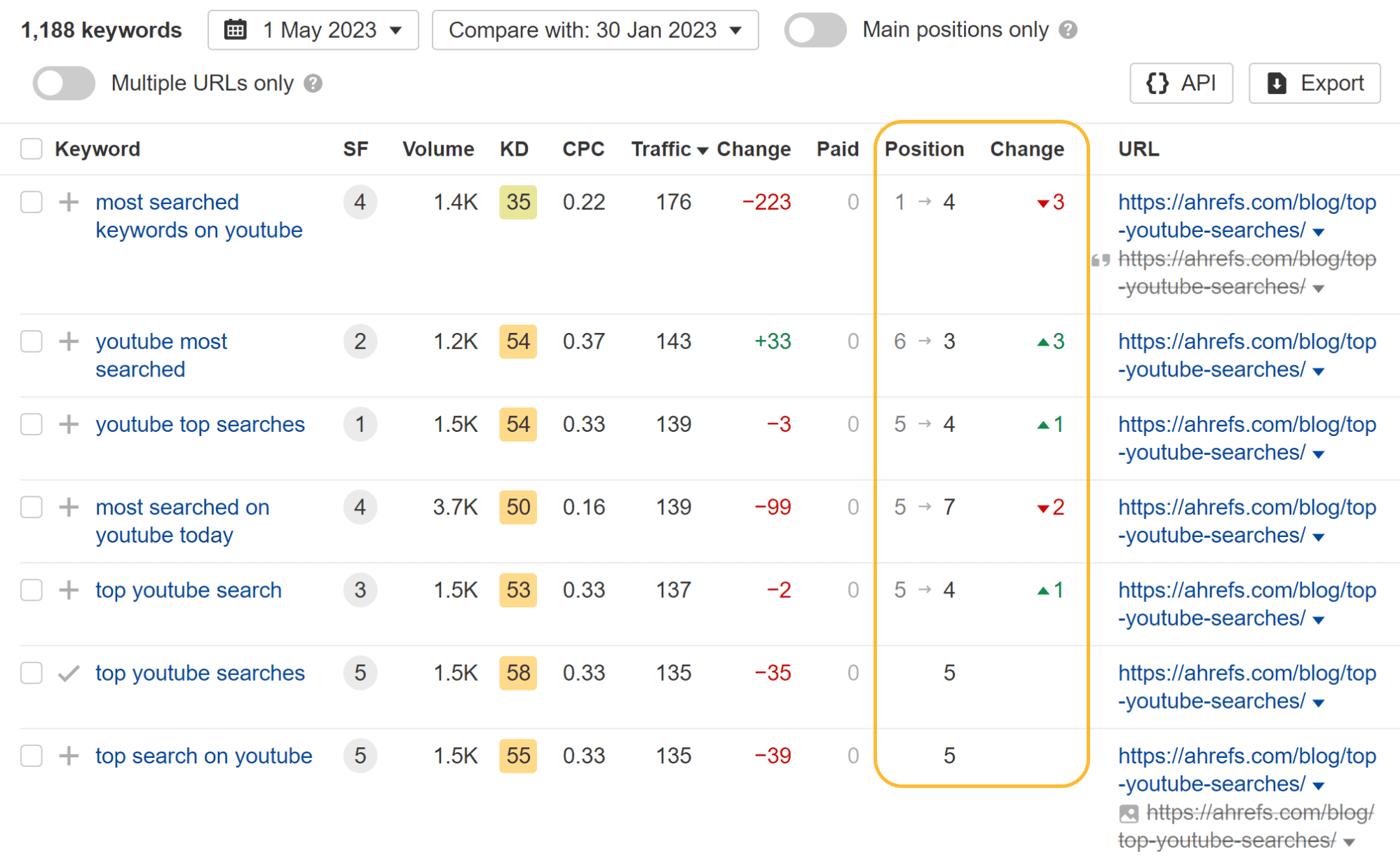
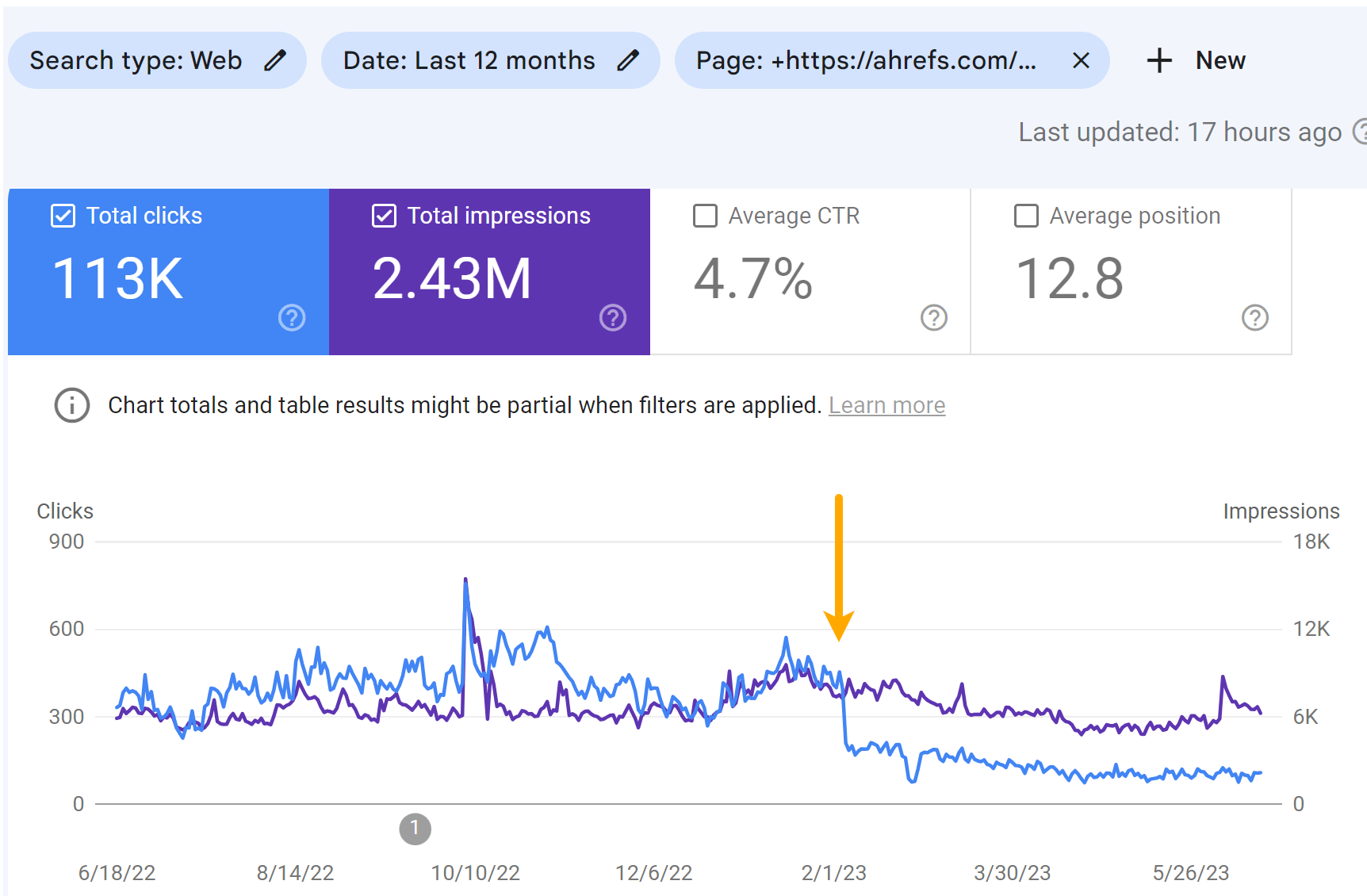
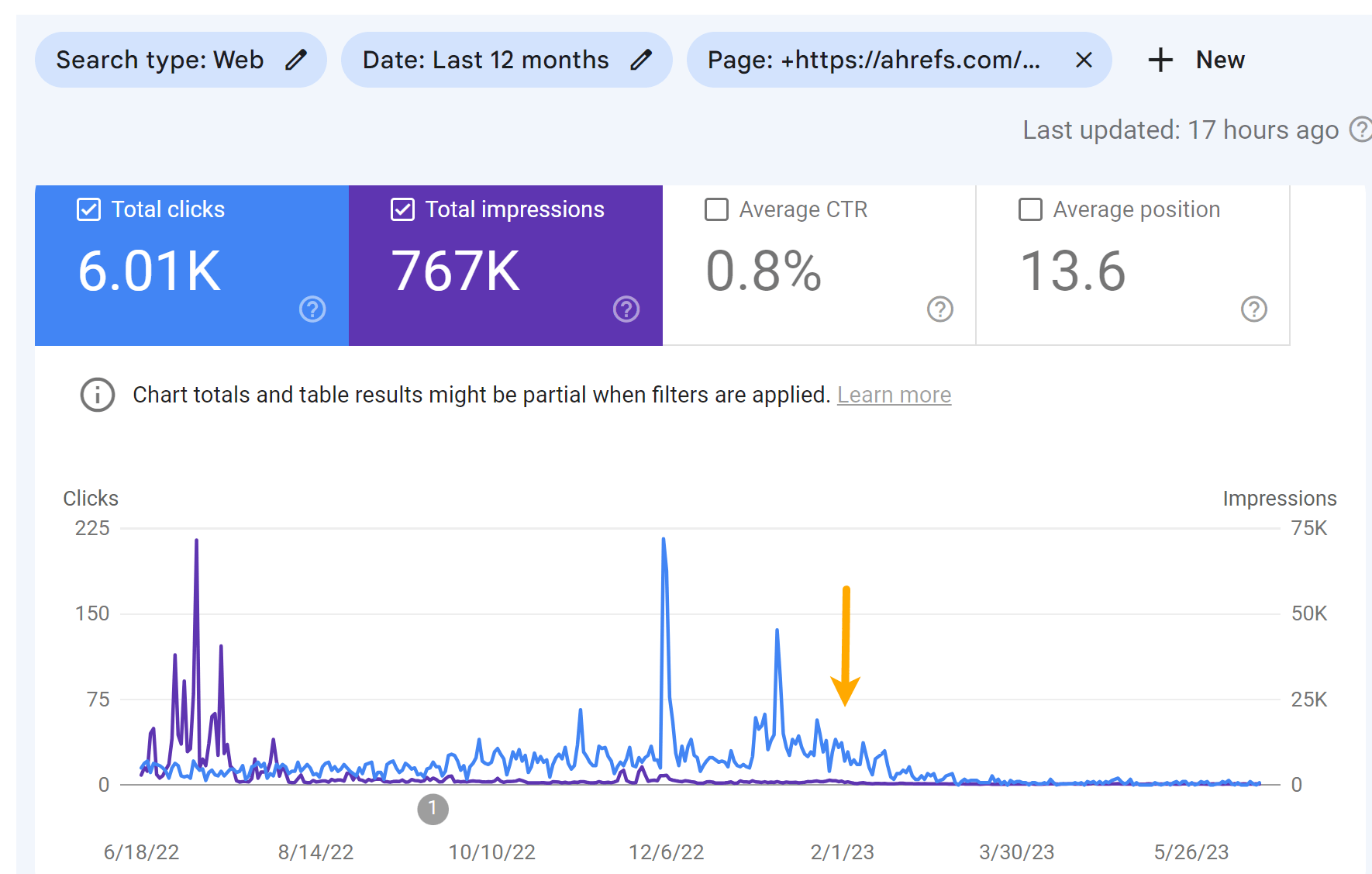
As you can see in the charts below, both pages lost some traffic. But it didn’t result in much change to our traffic estimate like I was expecting.
Looking at the individual keywords, you can see that some keywords lost a position or two and others actually gained ranking positions while the page was blocked from crawling.
The most interesting thing I noticed is that they lost all featured snippets. I guess that having the pages blocked from crawling made them ineligible for featured snippets. When I later removed the block, the article on Bing searches quickly regained some snippets.
The most noticeable impact to the pages is on the SERP. The pages lost their custom titles and displayed a message saying that no information was available instead of the meta description.
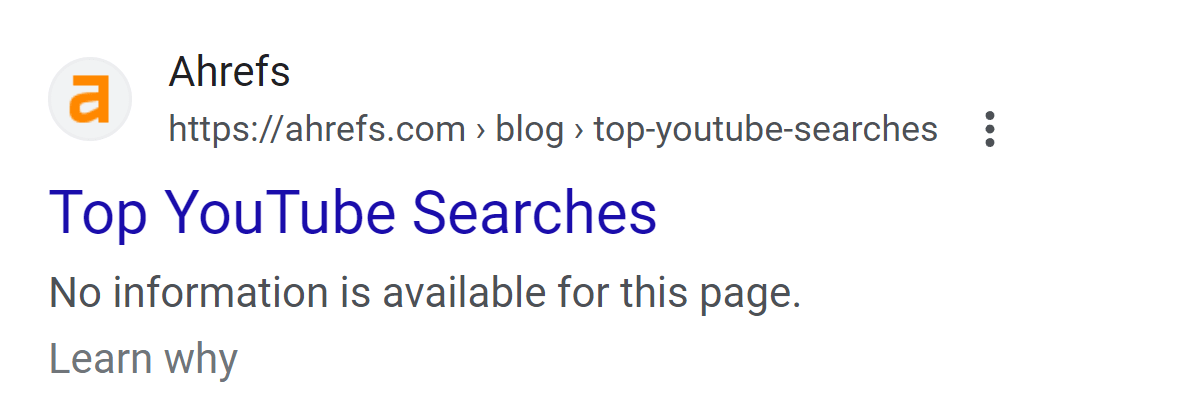
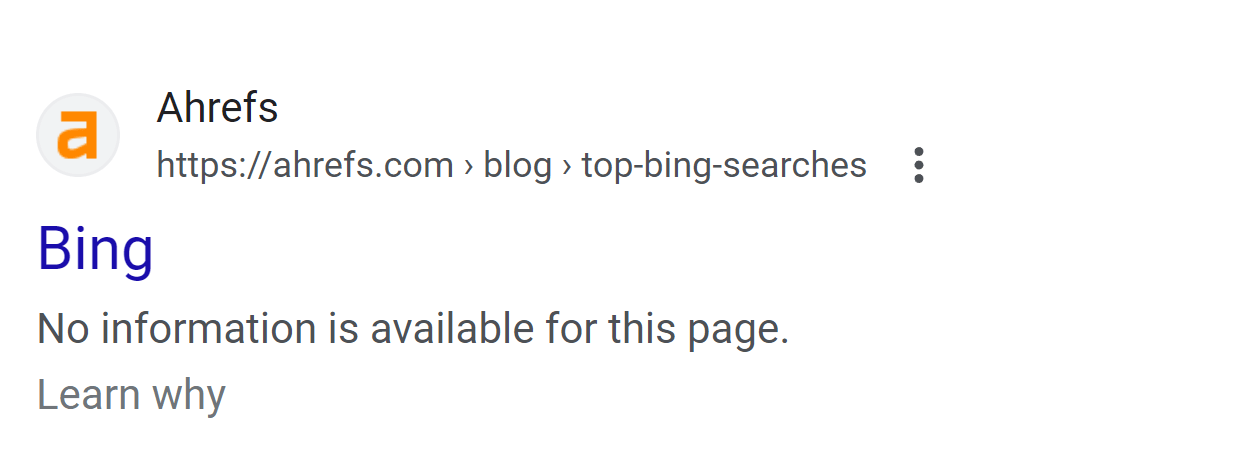
This was expected. It happens when a page is blocked by robots.txt. Additionally, you’ll see the “Indexed, though blocked by robots.txt” status in Google Search Console if you inspect the URL.
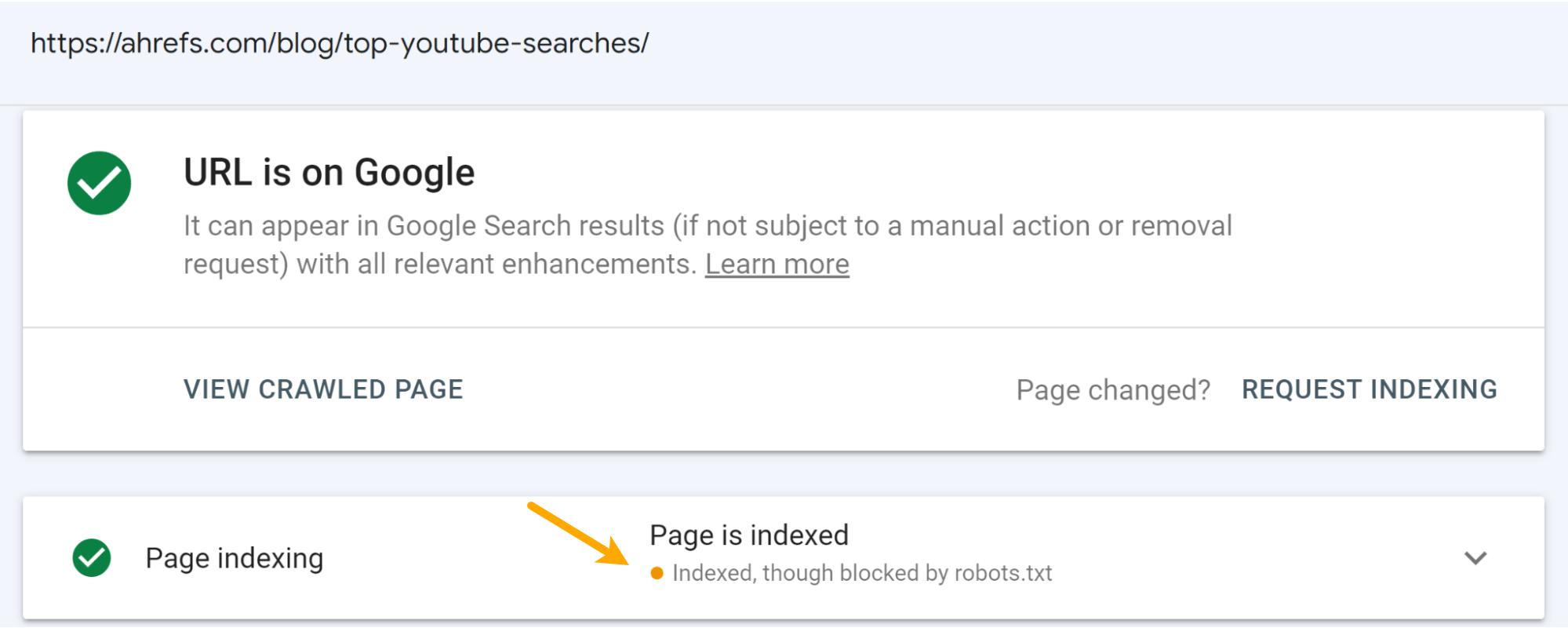
I believe that the message on the SERPs hurt the clicks to the pages more than the ranking drops. You can see some drop in the impressions, but a larger drop in the number of clicks for the articles.
Traffic for the “Top YouTube Searches” article:
Traffic for the “Top Bing Searches” article:
Final thoughts
I don’t think any of you will be surprised by my commentary on this. Don’t block pages you want indexed. It hurts. Not as bad as you might think it does—but it still hurts.